
The Rise of GPTBot: OpenAI’s Web Crawler sparks debates on Content Access
- TM Staff
- November 3, 2023
In recent days, the AI community has been abuzz with discussions surrounding OpenAI’s latest tool, GPTBot. This newly introduced web crawler is designed to scan website content to further train its large language models (LLMs) like ChatGPT. However, not everyone is on board with this innovation, as many website owners and news publishers have voiced concerns regarding unauthorized access to their content. This development has spurred a series of debates on content access, intellectual property rights, and the ethical implications of AI training methodologies.
OpenAI took a discreet approach, adding details about GPTBot to its online documentation without an official announcement. GPTBot operates as the user agent for OpenAI, retrieving web pages to train the underlying AI models powering ChatGPT. The introduction of GPTBot has provided website owners with an option to block OpenAI’s web crawler from accessing their pages, a choice that several have already exercised. The rising concern among website owners centers around the preservation of their intellectual property rights, fearing that AI models like ChatGPT might utilize their content without proper authorization or credit.
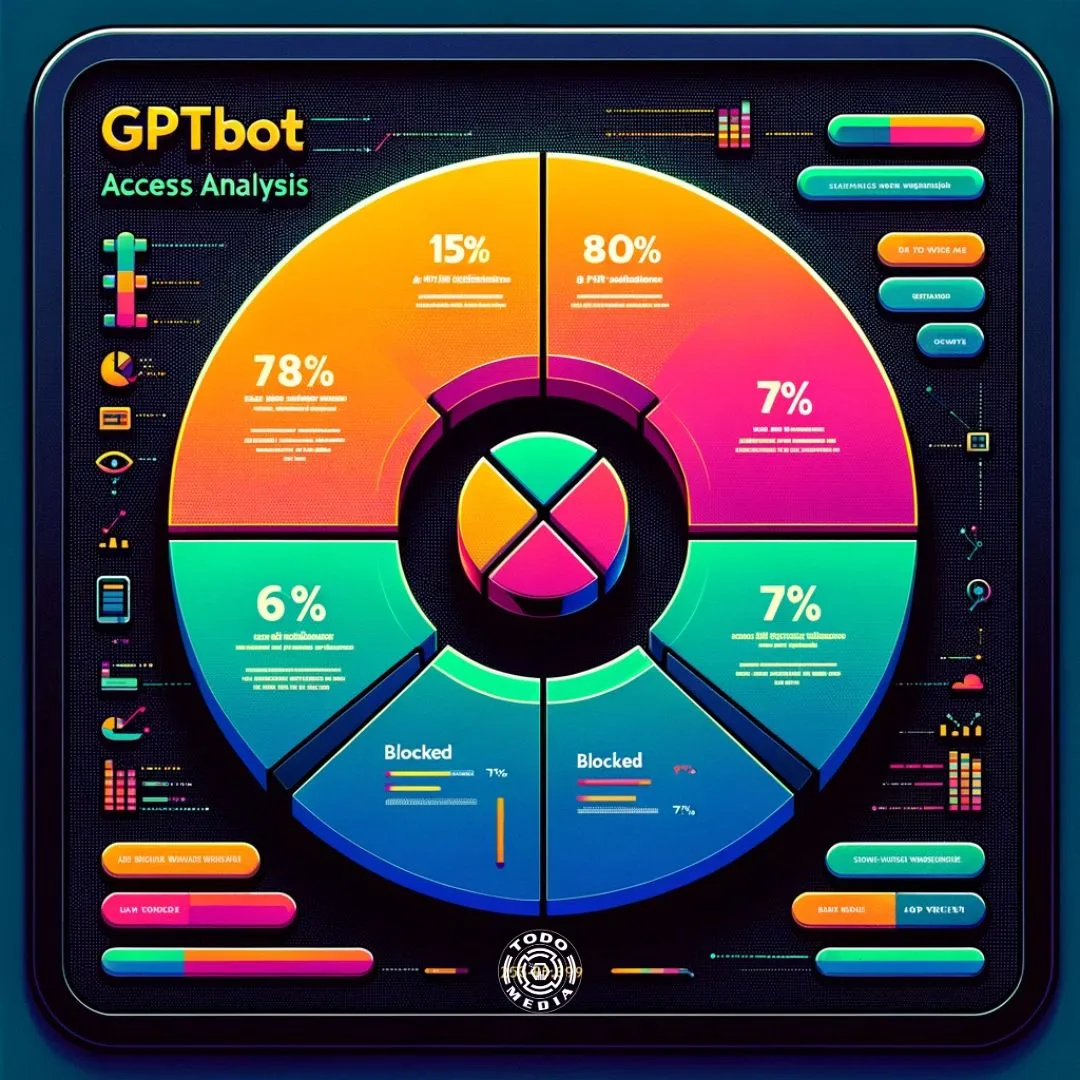
An analysis revealed that at least 15% of the top 100 websites and 7% of the top 1,000 websites have chosen to block GPTBot, a clear indicator of the trepidation surrounding this new tool. The concerns are not baseless; the ability of AI to access, utilize, and potentially repurpose content opens a Pandora’s box of legal and ethical questions. The central issue revolves around the potential for AI to inadvertently infringe upon copyright laws, a scenario that could lead to legal battles down the line.
In response to these concerns, OpenAI has published Robots.txt standards for blocking GPTBot, providing a guideline for those who wish to prevent the crawler from accessing their content. This move reflects a step towards addressing the concerns of the online community and establishing a middle ground. By offering a choice to website owners, OpenAI has opened a dialogue that could lead to broader discussions on the ethical training of AI models and the protection of digital content in the age of AI.
As we navigate through the uncharted waters of AI advancements, the actions of OpenAI and the response from the online community provide a fascinating glimpse into the future. The ongoing discourse surrounding GPTBot serves as a reminder of the delicate balance between innovation and ethical responsibility, a balance that will undoubtedly continue to evolve as AI technology progresses.
This unfolding scenario underscores the necessity for a collaborative approach between AI developers, website owners, and lawmakers to establish clear guidelines that safeguard intellectual property rights while promoting responsible AI development.


